As a software engineer, have you ever faced a complex project where every task seems to depend on another? My team at HashiCorp ran into just that — and found a method that helped us tackle those interdependencies in a way that lets us make smooth progress. Here’s how the Mikado Method improved our workflow.
The Challenge Link to heading
About a year ago, my team at HashiCorp tried something new. Our small team was beginning development on a new capability that would require changes to several libraries and a web service, with lots of interdependencies between them. To complicate matters, other teams were waiting on parts of our work to start theirs. We wanted a way that we could all make progress in parallel without the risk of constantly getting blocked by unfinished dependencies.
I had stumbled across the Mikado Method online a couple of years earlier. I tried it while working for my employer at the time, and I found that it helped me refactor code in a focused way. At HashiCorp, we decided to trial it as a team for this new project, and it worked so well that we’ve integrated it into our process for most projects since. It has boosted our team velocity, simplified code reviews, and enabled us to split work more efficiently.
What is The Mikado Method? Link to heading
The creators of the method, Daniel Brolund and Ola Ellnestam, describe its purpose in the preface to their book:
The Mikado Method is our guide to morphing [software systems]. It helps us visualize, plan, and perform business-value-focused improvements over several iterations and increments of work, without ever having a broken codebase. It enhances communication, collaboration, and learning in software development teams. It also helps individuals and programming pairs stay on track while doing their day-to-day work. The framework that the method provides can help the whole team morph any system into the desired new shape.
At its core, the Mikado Method is very straightforward. In fact, I feel like the essence of the technique is probably the kind of thing that some engineers would do intuitively and never think to give it a name. But it does have just enough rigor that it is easier said than done.
How it Works Link to heading
The process is essentially this, assuming you start from a point where you need to add some behavior to your code. You’ll need some paper, a whiteboard, or drawing software, so keep it handy!
- Start a new development branch in your version control system of choice. (I’ll assume git.)
- On your paper, jot down a quick description of the behavior you’re adding inside a circle — no need for long explanations.
- Attempt to implement the new behavior naively and quickly.
- ✅ If it works: You’re done! Commit the change (or open a PR), put a big check mark on the task on your drawing, and move on to the next task!
- 🛑 But if it gets too complex: Stop. GO TO STEP 4.
- Stop and think about the things that are getting in your way. What kinds of things would be helpful if they had already been completed, which would allow you to trivially make progress on this task. Taking a term I’ve heard from John Arundel, are there any “magic functions” that would help you? In other words, if only some function existed already that did X, then implementing this current behavior would be much easier.
- Decide which one(s) of the ideas you had in step 4 would be most helpful to you. Then, draw a circle on your paper for each of them, again with short descriptions. Draw a line from the task you were working on to each of these, with an arrow pointing at the new tasks. These arrows indicate that these tasks should actually be done before the current one.
- Now for the hard part: Delete your current development branch (yes, delete it!). Start on one of the pre-requisite tasks. Repeat the process as needed, diving deeper into dependencies.
Delete My Work, Huh?? Link to heading
Deleting changes you’ve been working on can be difficult! If you really can’t bring yourself to delete it, stash it, but I encourage you not to do this! You might feel like you’ve made good progress, but continuing on down the rabbit hole can lead to unreviewable pull requests for your team and a lot of cognitive load for yourself.
You might be worried about how you’ll remember what you previously did. That’s what the graph is for. You’ll still have a record of what you needed in the little circle you drew in step 2. You can come back to it once all of its pre-requisites are complete.
Aside: Even though I’ve used the technique for a while now, I still fall victim to thinking I’m “just about done” and keep digging myself into a deeper hole every now and then. Each time I do this, I come away wishing I had just deleted my branch, made some new tasks, and stuck to the process.
Recursive Exploration: Turtles All the Way Down Link to heading
You may also (correctly!) observe that this process is recursive. The pre-requisites can, themselves, turn out to have pre-requisites of their own. I like to think of the method as a depth-first search of all of the pre-requisites. Once you get to the farthest depths, you’re finally at a point where you can make code changes. The farther down you go, the better you also tend to understand the existing code and how best to change it!
Unplanned Interruptions? No Problem Link to heading
In addition to making the code changes small and manageable, there is another key benefit to this approach. Let’s say you make a few small changes, but then something happens, and you have to shift gears. Maybe you have personal commitments come up, work priorities change, or whatever the case may be. Well, when it’s time to come back to the thing you’re working on, you will have made some actual progress (small chunks of code already added to your code base), without having to try and reload all the context of a huge development branch into your head.
This small, incremental progress, is especially great when you’re working on Tech Debt. Fixing Tech Debt is important, can be quite difficult to finish, and is also likely to get bumped by feature development in corporate settings. (Not talking about my employer here! 😄) And, if you’re working on a team, and a colleague is able to pick this back up before you, then they have your contributions already, plus that chart you created, and they can find a task to work on, themselves.
An Example Link to heading
The Mikado chart is the critical artifact from the method, so let’s consider an example, even if it is a bit contrived. Let’s say you have written a command line interface application that counts the number of lines in a document. As great as it is, you feel like it would be even better if it could count the words in documents too, though! You’d like for users to be able to give it a file, tell it that they want to know the number of words, and it obeys.
Deciding to give the method a shot, you write down a brief description (“Add Word Count Mode”) to your paper and get started. You start writing code and before long realize a couple things: 1) You have your current implementation all directly within the main function; and, 2) You don’t have a way to actually tell whether a user wants lines or words. So, you draw a couple pre-requisites for these.
You decide to move down a level and explore counting words when the user provides a flag, -w. Unfortunately, your program doesn’t parse flags yet, and even if it did, it would be better to call a function to count words rather than putting this into main. Now you start on the function to count words, and you decide, “Hey, it sure would be nice if I could get a list of the words in a string, where each element was the text in between spaces.”
Before long, you have something that looks maybe, sort-of something like the drawing below.
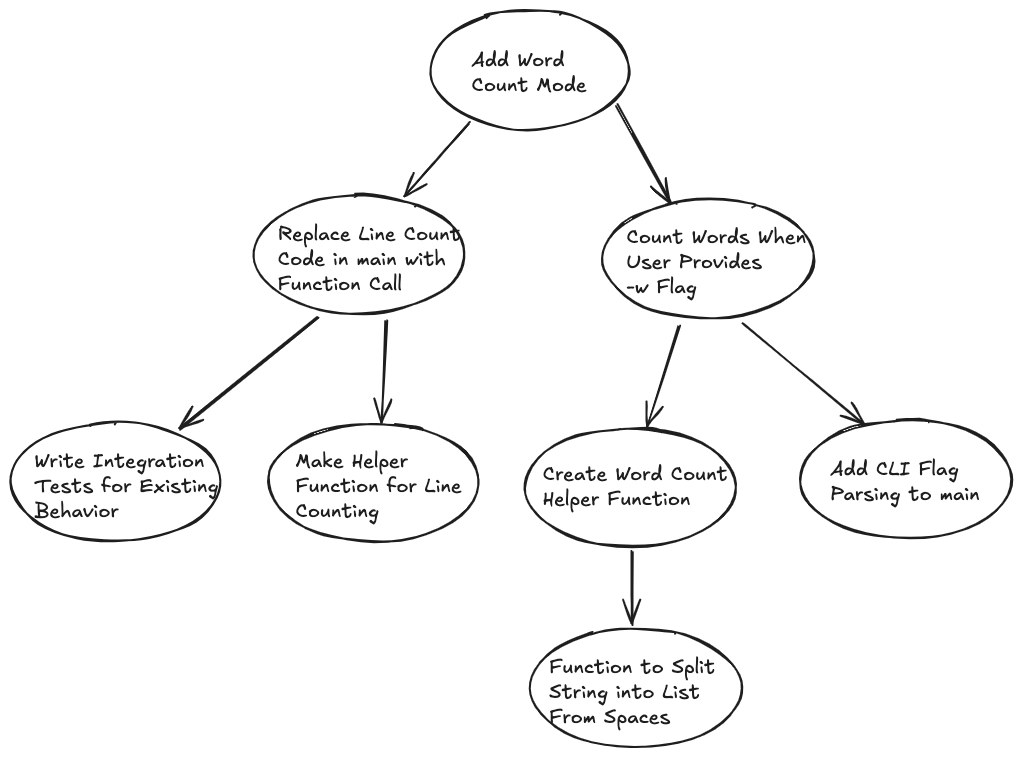
It’s a somewhat trivial example and probably misses some actual steps that a person would find if they were to actually need to implement such functionality. But hopefully this helps to demonstrate what a Mikado chart looks like and how it shows interdependencies.
How We Use the Mikado Method for Project Planning Link to heading
The description above is how an individual or team could deconstruct work into smaller chunks as they are developing a capability. But how do we use it for project planning? Well, actually not that differently to be honest!
As with most teams at HashiCorp, before we commit to implementing major capabilities, we document how a system or feature should work at a high level in Requests for Comments. Documents, though, are very linear. They describe how the overall system should work, but they aren’t project plans. We use the Mikado Method to get us from the proposal of an RFC to a set of tickets in our project tracking system (we use Jira) that the team can work on collectively.
We are a remote team and have folks working across time zones. So, we keep our Mikado charts online. We use LucidSpark for this, which allows us to all see any changes to the chart in realtime, and it also has the added benefit of a Jira integration that makes it quite easy to create tickets from items on the board.
Initial Draft Link to heading
Typically, if one person on the team was the lead author of a particular RFC, that person will take a first pass at a Mikado chart, with the overall goal at the top of the chart and ever-smaller subcomponents below, with arrows to appropriately indicate dependencies. A common practice is to “spike” a bit, where we might begin writing pseudocode with references to the magic functions that would help achieve the goal. Once we have some ideas of these functions, we iterate on that process for each of those. We don’t expect that this draft will be fully complete, but it generally serves as a great starting point.
Team Review Link to heading
Once we have this draft, the team will review it together on a Zoom call. The person who created it will walk through the chart, either bottom-up or top-down, and describe the thought process. There are usually lots of questions, folks will find things missing, the short task descriptions will be made clearer, and we end up with a chart that we all feel represents the work to be done and how each task affects other tasks. It’s also common that other members of the team have created charts for features that could potentially benefit from some of the tasks here, and we sort out those as dependencies as well.
Ticket Creation Link to heading
After we’ve met and agreed on the overall plan, the chart creator will go through and create Jira tasks to correlate to each task in the chart. Again, this is just a matter of tooling, and we are pretty happy with LucidSpark for this since it integrates well with Jira. We’re careful to ensure the tasks in Jira are linked appropriately (e.g., “task Y is blocked by task X but blocks task Z”).
Time to Code! Link to heading
Then, when it’s time to work on the feature, we almost always have several unblocked, small chunks of work, and anyone on the team is free to pick up and work on any of those tickets. If someone picks up a ticket and finds that it actually isn’t quite as cut-and-dry as expected, then they go back through the Mikado process for this particular task, dividing it up further, adding it to the chart, and creating more tickets as needed. As pre-requisites are completed, more tickets become unblocked, and we iterate on this process until we’re finished.
Conclusion Link to heading
We have gone through this process as a team several times by now. We have found that it allows us to make fast progress on both new feature development as well as general maintenance work. It also helps us to get everyone working in similar areas of code, which helps with knowledge sharing; it’s less common that one person develops a whole subsystem and becomes the only person who understands it.
If you’re looking for a way to tackle your next project, give the Mikado Method a try - it just might change how you work!